Introduction
For a long time we had a small infrastructure running. One server that hosted a few applications in docker containers and a very small vps with prometheus, alertmanager and grafana as systemd services.
As we progressed in my knowledge and my curiosity regarding infrastructure as code grew, we wanted to take my infrastructure to the next level.
Architecture
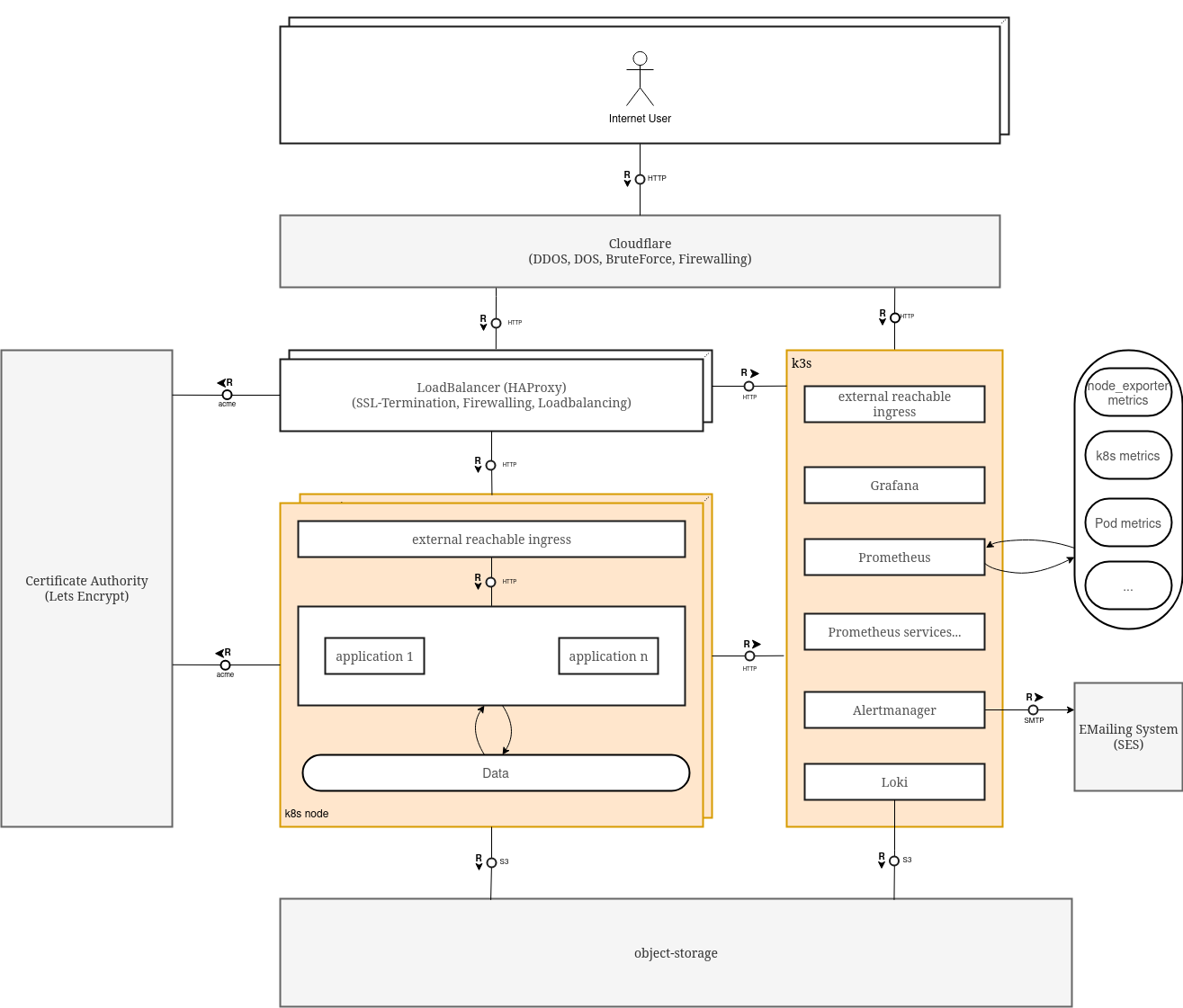
Everything colored in grey are external services that we manage them with terraform.
The kubernetes nodes, as well as the k3s instance are running ofcmyse on idependent vps, which are provisioned with terraform and configured with ansible.
Infrastructure as Code
We handled the whole provisioning and configuration of my infrastructure as code.
Cloud provider provisioning
The provisioning of my cloud providers is handled with Terraform.
When OpenTofu will reach a stable version we will migrate.
Currently we are lacking automated testing on this side, a goal of us is to use something like Terratest.
But this is a whole other topic for itself.
We use cloud-init for some pre installations and settings.
Infrastructure configuration
Configuration of my servers and kubernetes is handled with ansible.
We implemented on some roles tests with molecule, but we are not yet satisfied with the quality of the tests and we need to rework them.
my ansible roles will be soon-ish, one after the other, published on github. Then we also want to run the molecule tests regulary on github actions.
To deploy applications to my kubernetes cluster we decided to use ansible as well, for a few reasons:
- We already have the majority of my configuration in ansible like the FQDNs for the applications as we provision my HAProxy with ansible
- We configure the database for the applications with ansible
- We are able to execute one playbook that sets up a kubernetes cluster with all default applications we need like, cni, csi, metric server…
We wanted to ensure that the configuration of my infrastructure is consistend and continously applied, that’s why we installed AWX.
AWX is running inside my kubernetes cluster and continously executes my playbooks to all my maschines.
Running AWX inside the cluster which also gets provisioned by AWX could be problematic as a wrong configuration could break the cluster, but we decided to go this way anyway and put even more effort into testing my configuration.
Main k8s cluster
External accesibility
Each node has an external ingress controller. Its reachable via a NodePort.
In front of my kubernetes cluster we have HAProxy which is loadbalancing the incomming traffic to my kubernetes.
We decided against loadbalancing services from cloud providers as these are too expensive for us.
Would we have full control over the network, we would have tried to use MetalLB.
In front of HAProxy we configured Cloudflare to:
- Have protection for DOS- DDOS attacks
- Hide my IPs
- Do some firewalling
Data handling
As container storage interface (csi) application we decided to use Longhorn.
There was not really a decision process, as it is the defacto standart for csi and offers all features we needed.
Longhorn takes care of backing up my persistence volumes to an object-storage.
As database we deployed a single node postgres inside the kubernetes cluster and only accesable from inside the cluster.
We want to replace it in future with a high available deployment. For the ha setup we want to evaluate the zalando postgres operator and bitnami postgresql ha helm chart.
We wanted to have the postgres data backuped as plain sql. So we run a kubernetes cronjob, which dumps the data and backs it up to s3.
Monitoring system on k3s
Half of the monitoring stack was already running as systemd services, but we decided that kubernetes should be my default platform to run applications.
So we decided to move pormetheus, alertmanager, etc. from systemd services to deploy in them in k3s and also added loki.
And now that these services are also kubernetes deployments, we are can handle them the same as the other applications.
To make everything externally available we just used traefik it also brings TLS encryption out of the box.
To tackle the problem of missing out if the monitoring server goes down, we deployed grafana on the main kubernetes cluster and configured prometheus and loki as datasmyces. We added alerting for the case that the datasmyces have no data.
An alertnative instead of setting up and maintaining the stack by myselfs would be using grafana cloud and there free tier.
The stones on my way
One mistake, that we have done is that we added ssh keys via cloud-init.
This leads to the problem, that on every ssh key we replace or want to add in cloud-init, terraform wants to destroy my instances.
We also handle ssh keys with ansible and still need to fix this behaivor.
Future
We have a lot of ideas and plans for my infrastructure, of cmyse! Here are some ideas:
- A CI/CD platform, we will anyways need a CI-Server for automation and we really want to play around with ArgoCD
- Automated updating and testing of updated infrastructure and applications
- Automated backup testing
- Doing load tests on my applications to improve performance and scalability